|
part of an author’s style is manifest in the frequency with which particular words are used. An individual author’s patterns of word choice tend to be consistent from one text to another, and these patterns can be measured. An aggregation of word frequencies, called a vocabulary profile, can be derived from texts known to be written by a particular author, and then used to analyze other texts, possibly of unknown authorship. Previous studies have shown that a vocabulary profile derived from novels by a particular author can bear a strong correlation to the vocabulary profiles of other novels by the same author. This study demonstrates that the vocabulary profiles of the letters of Jane Austen, Fanny Burney, and Maria Edgeworth closely resemble the vocabulary profiles of the novels of each of these authors.
For several years I have been writing software to analyze the texts of Jane Austen’s novels and letters to explore patterns in word frequency, and I don’t think that Jane Austen would have objected. She often played with words herself. Consider this letter (11 June 1799) to Cassandra: “We walked to Weston one evening last week, and liked it very much. Liked what very much? Weston – no – walking to Weston.” Or this letter (8-9 November 1800) to Cassandra, also illustrating Jane’s enjoyment of word play: “So much for that subject; I now come to another, of a different nature, as other subjects are very apt to be.” In fact, Jane even refers to word frequency herself, as in this letter (16-17 December 1816) to James Edward Austen: “You must not be tired of reading the word Uncle, for I have not done with it.”
Before proceeding further, it is appropriate to set the context with a brief history of word frequency analysis research spanning the last sixty years.
A brief history of word frequency research
The accomplishments of early word frequency researchers are astounding, considering that they did their work by hand, cataloging results on index cards. Researcher G. Yule, tabulating word frequency, letter frequency, and sentence length by hand in the 1940s, was able to conclude that “separate samples from the same author resemble each other much more closely, in respect to alphabetical distribution, than samples from the two distinct authors” (193). Yule concluded: “My impression is that inclusion of all words without exception would be a mistake; that the inclusion of the and is and the like, each with a very large number of occurrences in any author, would merely tend to obscure differences, and it would be best to limit data to what are in some sense ‘significant words’. But this is pure speculation” (281).
In the 1960s Alvar Ellegård read texts, tabulating the occurrences of certain words that he had fixed in his memory, working up to a list of over 450 words. He related, “At first I did not believe it would be possible to remember so many words, and started with a list of about a hundred, which was gradually increased” (23). Ellegård found that certain words, such as this, that, on, and upon worked well as vocabulary profile words, and that the words sometimes formed pairs or groups of “alternative expressions, of the type on – upon. If one of those words turns up on the positive side, the other is likely to appear on the negative side” (44). Ellegård concluded that vocabulary profiling could correctly select “practically all” of an author’s texts while rejecting texts by other authors (77). Building on the foundation set by Yule twenty years earlier, Ellegård’s conclusions indicate significantly higher confidence in the use of vocabulary profiling in identifying text authorship.
Andrew Morton was drawn into statistical analysis of texts to advance his study of the Greek texts forming the New Testament. In the 1970s, he applied his methodology, which he named “stylometry,” as an expert witness on the authenticity of a defendant’s written statements. Morton confidently defined stylometry as “the science which describes and measures the personal elements in literary or extempore utterances, so that it can be said that one particular person is responsible for the composition rather than any other person” (7). Clearly, Morton had no doubts that a vocabulary profile could be used to identify the author of a text.
During the 1980s, John Burrows analyzed the spoken text of characters in a dozen novels, including all the major characters of Jane Austen's novels, and plotted the results with each character represented as a point on a graph, such that characters with similar word usage were plotted more closely together. He noted “the characters of each novel make a distinct ‘family group,’ attesting to underlying differences between novelist and novelist in the style of dialog” (161). While Burrows contemplated the idea that word frequencies could uniquely identify an author, he stopped short of making a definitive statement that it was possible, stating only that prior studies “cannot lightly be dismissed” (99).
Stirman and Pennebaker in 2001 reported evidence that word frequencies in written text could be an indicator of psychological state. They studied the poetry of suicidal versus non-suicidal poets and sought to test the viability of various models of suicide, including the Durkheim model, in which the suicidal individual has failed to integrate into society sufficiently and is therefore detached from social life. They found evidence to support the social integration model; most notably, the suicidal group used more first person singular words (such as I, me, and my) than the control group. The authors theorized that poetry may be an appealing medium for coping with mood swings, or that writing poetry may be harmful to the psychological health of the poet. One is reminded of Anne Elliot’s conversation with Captain Benwick: “she ventured to hope he did not always read only poetry; and to say, that she thought it was the misfortune of poetry to be seldom safely enjoyed by those who enjoyed it completely; and that the strong feelings which alone could estimate it truly were the very feelings which ought to taste it but sparingly” (100-101). From this passage, one might conclude that Jane Austen was a naturally intuitive psychologist, among her other talents! She was certainly a keen observer of human nature. While Stirman and Pennebaker focused on analyzing an author’s personality and not on identifying authorship, their process depended on word frequency analysis and creation of vocabulary profiles for the authors under study.
In my presentation at the 1999 Annual General Meeting of the Jane Austen Society of North America, I described my early work in word frequency analysis, and my own conclusion that word frequencies in texts by the same author are closely correlated. In that paper, I described how it first occurred to me that a computer could be used to analyze the text of novels. “A profile of word usage could be generated, and profiles of different texts could be compared. Perhaps this could give new insight into a particular author’s craft” (206). When this idea first occurred to me, I naively thought that I might be onto something new. Little did I know that many others had thought of word frequency analysis, many years ago, as demonstrated by this brief (and necessarily incomplete) history.
Profiling the letters and novels
My methods compare the word frequencies of two or more texts by the same author, to develop a profile word set for each author that can be used to distinguish works by that author from those of other authors. Over the last several years I have found that each of the sample novels should have 25,000 words or more, in order to construct a useful vocabulary profile that will accurately represent a particular author’s word choice habits. All of the novels in this study well exceeded this limit, with Northanger Abbey as the smallest sample at about 77,000 words. Samples of unknown texts (or texts that will be treated as if they are unknown samples) can be as small as 10,000 words, but larger is better. My prior work on appropriate sample sizes led to my decision to combine the letters for each author, in order to have accurate representation of vocabulary habits for each author’s letters. For this study, each collection of letters well exceeded the 10,000 word minimum, with Edgeworth’s letters forming the smallest sample at about 89,000 words.
Fanny Burney and Maria Edgeworth were the authors chosen for comparison, since they were contemporaries of and admired by Jane Austen. The choices of texts used in this study of letters and novels were based largely on availability of texts in an electronic format. Fanny Burney’s novels Camilla, Cecilia, and Evelina were used. Maria Edgeworth’s novels The Absentee, Belinda, and Helen were used. Jane Austen’s six complete novels were used. The novels for the three authors formed the control group; that is, the profiling software examined the texts of these novels to identify a set of words that works well for differentiating texts by different authors within the control group of Austen, Burney, and Edgeworth. After identifying the profile word set for the authors based on their novels, the letters were then introduced as the independent variable group and analyzed using the same profile word set.
Earlier researchers selected particular words to study, apparently discovering the most useful profile words by trial and error or by intuition. Instead, I discovered the significant vocabulary profile words via programs that examine millions of sets that include or exclude words from a master list of the five hundred most frequently used words. Each of these trial word sets varied in size, up to twenty words. For each word set, the corresponding sets of word frequencies for each text in a control group were evaluated using Pearson’s correlation coefficient. Word sets that resulted in a high correlation between texts by the same author in the control group were scored highly. After evaluating many word sets, a set of twelve words was chosen that best distinguish between the authors in the control group. Those words were then used to examine the letters. In other words, there was a process of calibration using texts in a control group before proceeding with vocabulary profiling of texts outside of the control group. This method still used trial and error, but with computer automation I was able to explore literally millions of sets of words in a relatively short amount of time.
Commonly used conjunctions and articles such as and, the, and a are poor choices for vocabulary profile words, because their frequency is so similar for most writers, and so high in general that they obscure the more subtle vocabulary patterns. While this phenomenon was the subject of speculation on the part of Yule in the 1940s, I have verified his hypothesis by running automated tests of millions of word sets.
It turns out that nouns, verbs and adjectives don’t work well when the object of word frequency analysis is author identification, because those words are closely connected to the particular subject matter of the sample text. Thus, a writer might frequently use the words ship, sail, and sea in a novel with a nautical setting, but would not frequently use those words in other texts.
So what types of words remain? Prepositions and adverbs turn out to be excellent words to include when creating vocabulary profiles. It is amusing that Austen noted the significance of such words, as she described the very unreserved Miss Holder in this letter (26 May 1801) to Cassandra: “She has an idea of your being remarkably lively; and therefore get ready for the proper selection of adverbs, and due scraps of Italian and French.” The frequencies of prepositions and adverbs tend to remain similar when examining multiple texts by the same author, while the frequencies can vary greatly from one author to another. For example, the words on and upon are useful as vocabulary profile words. Ellegård documented the usefulness of this pair of alternative expressions, and my work corroborates his finding.
In this study, the novels in the control group were analyzed to produce a profile word set that works well for differentiating the three authors. The resulting profile word set contained the words on, upon, again, already, till, enough, however, thus, that, then, where, and why. Figure 1 is a graphical representation of the profiles of the novels in the control group based on these twelve words.
To produce this graph, Pearson’s Correlation Coefficient was calculated for each pair of texts using the frequencies of each word in the profile set. Using a statistical technique called “Multi-dimensional analysis” the many correlation coefficients were processed into smaller lists of Eigen vectors, and the first two vectors were plotted. The three sampled novels for Burney and for Edgeworth appear as three points connected to form a triangle for each of the two authors. Austen’s six novels appear as six connected points. Texts with similar vocabulary profiles appear as points that are closer together, and the points for texts with dissimilar vocabulary profiles are further apart. This type of graph allows one to intuitively grasp the overall trends in the vocabulary profiles of the novels.
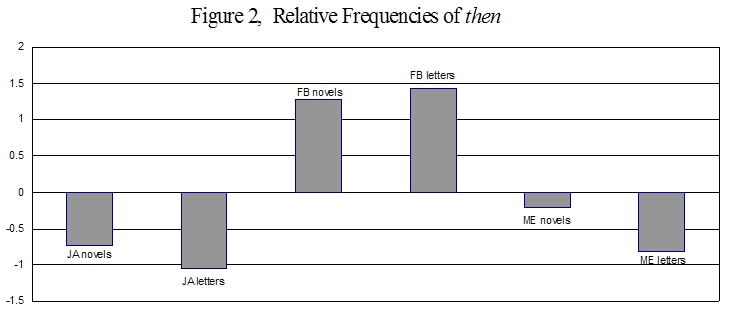
Having developed a profile word set from the novels, the letters were then analyzed using the same profile word set. To begin, let us consider the relative frequencies of the single word then in the letters and novels of the three authors, as shown in the histogram in Figure 2. The vertical axis ranges from negative, indicating word frequencies less than the median for the three authors, to positive, indicating frequencies greater than the median.
It can be seen that in her novels and letters, Austen used then less frequently than the median for these authors, while Burney used then more frequently. Edgeworth used then less frequently in both novels and letters, but the variation in her usage of the word between her novels and her letters was greater than for the other authors. Attempting to explain the significance of these differences in word choice seems futile. As Austen wrote in her letter (2 June 1799) to Cassandra: “Heaven forbid that I should ever offer such encouragement to explanations as to give a clear one on any occasion myself!”
It is clear that a one-dimensional analysis of the frequencies of a single word from the profile set is of limited use in differentiating authors. Two-dimensional analysis of the frequencies of a pair of words from the profile set can result in improved differentiation.
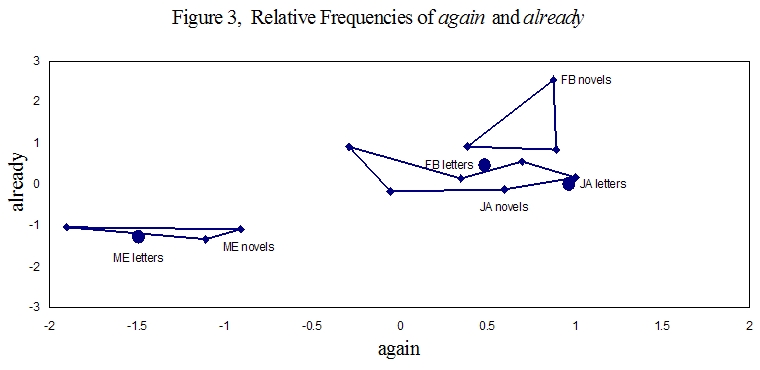
Figure 3 shows the relative frequencies of the words again and already for the sample texts. As before, the three sampled novels for Burney and for Edgeworth appear as three points connected to form a triangle for each of the two authors, and Austen’s six novels appear as six connected points. Each axis ranges from negative, indicating word frequencies less than the median for the three authors, to positive, indicating frequencies greater than the median. The collection of letters for each author forms a single text represented as a large dot, labeled with the initials of the author.
In Figure 3, the points representing Edgeworth’s texts lie in the negative range for both already and again, indicating that she used those words less frequently than the median. Austen and Burney used both words at a higher frequency, with Burney using the word already at a particularly high frequency. For all three authors, the frequencies of the words again and already in the letters are close to the values for the respective novels. Since Austen and Burney are similar in their habits for these two words, the letters and novels form a rather close cluster. From this graph it can been seen that a vocabulary profile based on only these two words could properly distinguish texts by Edgeworth from texts by Austen or Burney, but would not be useful for differentiating between texts written by Austen and Burney.
The relative frequencies of the words till and enough are plotted in Figure 4, where a greater differentiation of habits in word usage can be seen for the three authors.
In her novels, Austen used enough more frequently and till less frequently than the other authors, while for Burney the reverse is the case. Edgeworth used both words less frequently than the other two authors. The word selection habits hold true in the texts for the letters, except for Austen’s letters, where she used till much more frequently than in her novels.
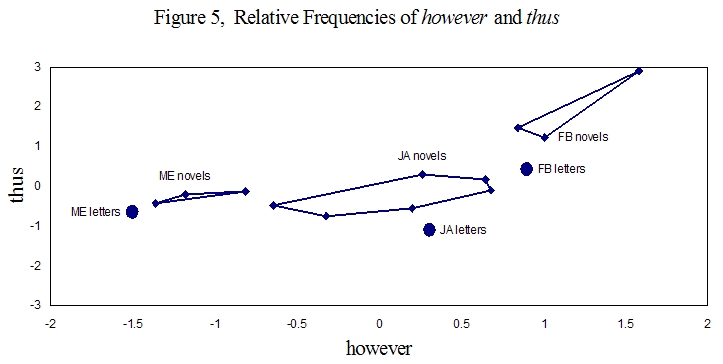
Figure 5 shows the relative frequencies of however and thus in the sample texts.
This graph shows Edgeworth and Austen used the word thus with approximately equal frequency, while Burney used it much more frequently. Edgeworth used however much less frequently than the others, and Burney used however much more frequently. The three points for the three collections of letters tend to be near the novels for each of the authors, but all three authors use the word thus less frequently in their letters than they did in their novels.
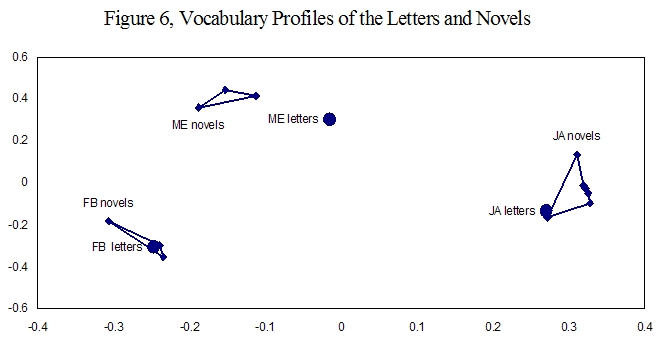
Let us return now to multi-dimensional analysis, introduced in the first graph. Figure 6 displays the same data as Figure 1, with the inclusion of the three points for the author’s letters. It shows a multi-dimensional vocabulary profile, using the full set of twelve profile words derived from the selected novels of Austen, Burney, and Edgeworth.
These results show that for each author, there is a good correlation between the vocabulary profiles of the letters and novels. The correlation is especially strong for Austen and Burney. The vocabulary profile of Austen’s letters closely matches that of her novels. For the twelve words profiled, Austen’s letters correspond most closely to Northanger Abbey. The point representing Pride and Prejudice is the most distant from the point for Austen’s letters, indicating the lowest correspondence, as compared to the other novels.
Similarly, Burney’s novels and letters show a close correspondence in their word usage patterns for the twelve profile words, especially in Camilla and Cecilia. Burney’s letters show a lower correlation with her novel Evelina.
The similarity in vocabulary profiles between Edgeworth’s letters and novels is not as strong, but the proximity of points clearly shows that there is a correlation. Note that the distance between the point for Edgeworth’s letters and the cluster of points for her novels is similar to the distance between Austen’s two most dissimilar novels or Burney’s two most dissimilar novels. Of the three Edgeworth novels analyzed, Helen bears the strongest correlation.
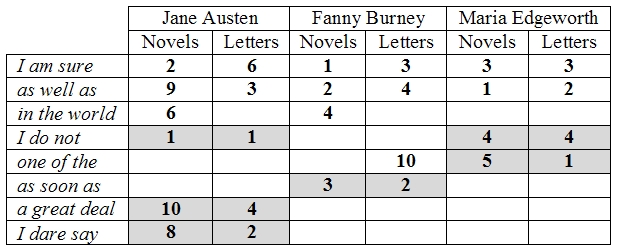
We now turn to analysis of sequences of words favored by the three authors, in both novels and letters. Through repeated experimentation, I have found that frequency analysis of short sequences of words gives better results for author identification than longer ones, because short sequences occur in significantly larger numbers, numbering in the hundreds. Using software to identify every recurring three-word sequence in the six categories of texts (letters and novels for the three authors), and then counting the sequences, the most frequently used sequences were identified. An analysis of the ten most frequently used sequences in each text is summarized in the following table, with the number one indicating the most frequent. An empty table cell indicates that the corresponding sequence does not appear in the set of the ten most frequently used sequences in that text.
The sequences I am sure and as well as are quite frequently used in the novels and letters of the three authors. Thus, these two sequences, being favorites of all three authors, are not useful as a tool to distinguish one author’s texts from another’s.
The sequence in the world is prominent in the novels of Austen and Burney, but not in the letters of the three authors. The sequence I do not appears frequently in the letters and novels of Austen and Edgeworth, but not in those of Burney. Now we are getting somewhere. Furthermore, I do not is the number one most frequently used three-word sequence by Austen in both the novels and the letters, while it is the fourth most frequently used by Edgeworth in both novels and letters. The sequence one of the appears frequently in texts of Burney and Edgeworth, but is used much more frequently by the latter. Thus, the frequencies of these four sequences can help differentiate texts by the three authors. The last three sequences show habits that are characteristic of a particular author. The sequence as soon as is distinctly Burney’s (in both novels and letters), while the sequences a great deal and I dare say are distinctly Austen’s. Analysis of the three-word sequences was not performed with the same mathematical rigor as the profiling of individual words, but the results still show a trend towards correlation of frequencies of three-word phrases in letters and novel.
This analysis of the vocabulary profile of Jane Austen shows a close correlation in the frequency of words and three-word sequences in Austen’s novels and letters, confirming the sense of familiarity felt by readers of both texts. The analysis also shows that the correlation in word usage in letters and novels is stronger for Austen and Burney than it is for Edgeworth. While it is unlikely that any new novels attributed to Austen, Burney, or Edgeworth will surface, these methods of analysis could be used to provide additional evidence of authenticity or fraud in the case of less famous authors. My hopes are that someday these methods could lead to giving proper acknowledgement to an early female author who published anonymously, not by choice, but because it was the only option. As Anne Elliot said: “‘Men have had every advantage of us in telling their own story. Education has been theirs in so much higher degree; the pen has been in their hands’” (234).
Works Cited
Austen, Jane. Jane Austen’s Letters. Ed. Deirdre Le Faye. Oxford: OUP, 1997. __________. Persuasion. Ed. R. W. Chapman. 3rd ed. Oxford: OUP, 1933. Burrows, John. Computation into Criticism: A Study of Jane Austen’s Novels and an Experiment in Method. Oxford: OUP, 1987. Ellegård, Alvar. A Statistical Method of Determining Authorship. Gothenburg: GUP, 1962. Graves, David Andrew. “Computer Analysis of Word Usage in Emma.” Persuasions 21 (1999): 203-11. Morton, Andrew Queen. Literary Detection: How to Prove Authorship and Fraud in Literature and Documents. New York: Scribner's, 1978. Stirman, Shannon and James Pennebaker. “Word Use in the Poetry of Suicidal and Non-Suicidal Poets,” Psychosomatic Medicine 63 (2001): 517-22. Yule, G. U. The Statistical Study of Literary Vocabulary. Cambridge: CUP, 1944.
|